

麦克风语音输入,经过语音转文本(Whisper),输出文本给大语言模型(Ollama、OpenAI、Kimi),大语言模型输出结果经过文本转语音(Edge-tts、F5-tts、CosyVoice、ChatTTS)通过喇叭播放文本内容。
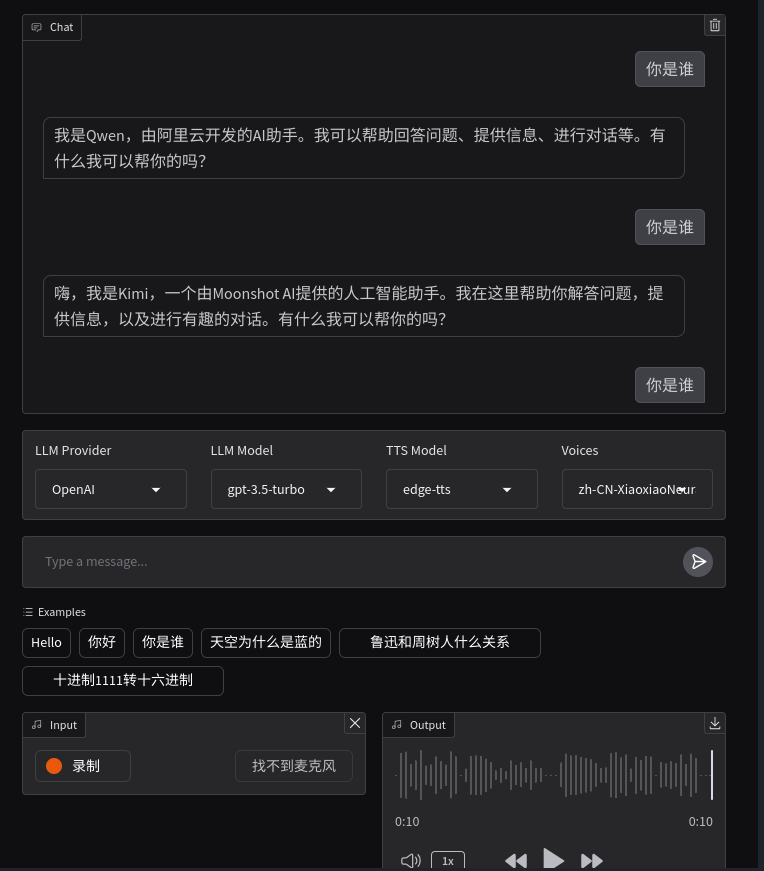
界面由Gradio创建,开启麦克风权限,选择TTS Model,点录制开始语音输入,录制结束点停止,开始语音转文件,转换结束文本输出给输入框,点提交开始问答。大语言模型输出结果经过TTS转成音频文件输出给Output并自动播放。
- Ollama使用本地模型文件
- OpenAI和Kimi在线交互
- F5-tts、CosyVoice和ChatTTS使用本地模型文件(GPU内存不够,使用CPU推理,慢)
- Edge-tts在线交互
测试地址: https://embedfeng.com/chat
效果图
评论区